![]()
Release v0.15
- Relational pipes
- Principles
- Roadmap
- FAQ
- Specification
- Implementation
- Examples
- License
- Screenshots
- Download
- Support & contact
We are pleased to introduce you the new development version of Relational pipes. This release brings two big new features: streamlets and parallel processing + several smaller improvements.
- SLEB128: variable-length integers are now signed (i.e. can be even negative!) and encoded as SLEB128
- streamlets in relpipe-in-filesystem: see details below
- parallel processing in relpipe-in-filesystem: see details below
- multiple modes in relpipe-in-xmltable: see details below
-
XInclude in relpipe-in-xmltable: use
--xinclude trueto process XIncludes before converting XML to relations - relpipe-lib-protocol → relpipe-lib-common: this module was renamed and converted to a shared library, it will contain some common functions instead of just the header files
See the examples and screenshots pages for details.
Please note that this is still a development release and thus the API (libraries, CLI arguments, formats) might and will change. Any suggestions, ideas and bug reports are welcome in our mail box.
Streamlets
Streamlet is a small stream that inflows into the main stream, fuse with it and (typically) brings new attributes.
From the technical point of view, streamlets are something between classic filters and functions.
Unlike a function, the streamlet can be written in any programming language and runs as a separate process.
Unlike a filter, the streamlet does not relplace whole stream with a new one, but reads certain attributes from the original stream and adds some new ones back.
Common feature of filters and streamlets is that both continually read the input and continually deliver outputs, so the memory requirements are usually constant and „infinite“ streams might be processed.
And unlike ordinary commands (executed e.g. using xargs or a shell loop over a set of files), the streamlet does not fork() and exec() on each input file – the single streamlet process is reused for all records in the stream which is much more efficient (especially if there is some expensive initialization phase).
Because streamlets are small scripts or compiled programs, they can be used for extending Relational pipes with minimal effort. A streamlet can be e.g. few-lines Bash script – or on the other hand: a more powerful C++ or Java program. Currently we have templates/examples written in Bash, C++ and Java. But it is possible to use any scripting or programming language. The streamlet communicates with its parent (who manages the whole stream) through a simple message-based protocol. Full documentation will be published when stable (before v1.0.0) as a part of the public API.
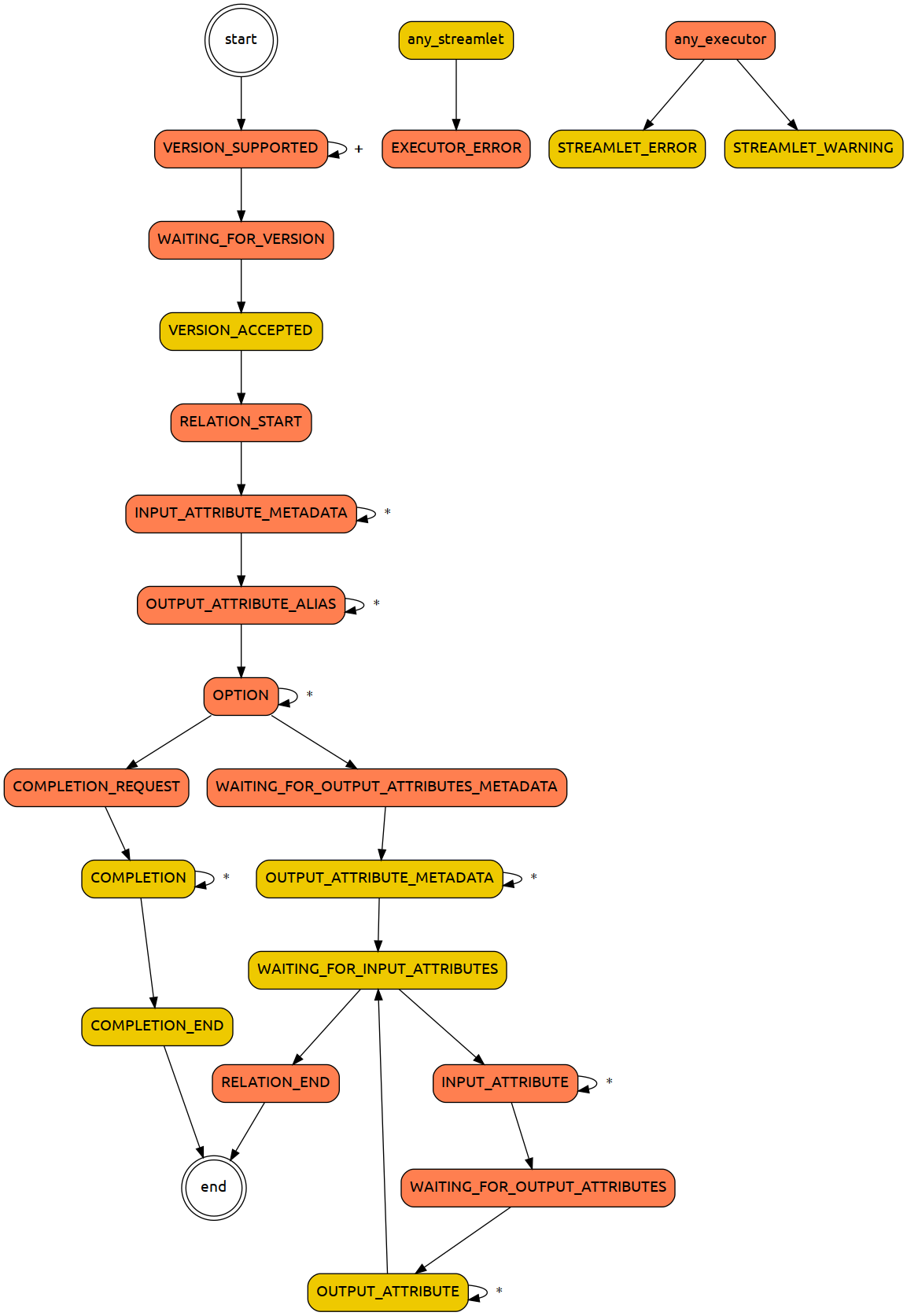{kind=link}
The first module where streamlets have been implemented is relpipe-in-filesystem.
Streamlets in this module get a single input attribute (the file path) and add various file metadata to the stream.
We have e.g. streamlets that compute hashes (SHA-256 etc.), extract metadata from image files (PNG, JPEG etc.) or PDF documents (title, author… or even the full content in plain-text), OCR-recognized text from images,
count lines of code, extract portions of XML files using XPath or some metadata from JAR/ZIP files.
The streamlets are a way how to keep relpipe-in-filesystem simple with small code footpring while making it extensible and thus powerful.
We are not going to face the question: „Should we add this nice feature (+) and thus also this library dependency (-)? Would it be bloatware or not?“.
We (or the users) can add any feature through streamlets while the core relpipe-in-filesystem will stay simple and nobody (who does not need that feature) will not suffer from the growing complexity.
But streamlets are not limited to relpipe-in-filesystem – they are a general concept and there will be relpipe-tr-streamlet module.
Such streamlets will get any set of input attributes (not only file names) defined by the user and compute values based on them.
Such streamlet can e.g. modify a text attribute, compute a sum of numeric attributes, encrypt or decrypt values or interact with some external systems.
Writing a streamlet is easier than writing a transformation (like relpipe-tr-*) and it is more than OK to write simple single-purpose ad-hoc streamlets.
It is like writing simple shell scripts or functions.
Examples of really simple streamlets are: inode (Bash) and pid (C++).
It requires implementing only two functions: first one returns names and types of the output attributes and the second one returns that attributes for a record.
However, the streamlets might be parametrized through options, might return dynamic number of output attributes and might provide complex logic.
Some streamlets will become a stable part of the Relational pipes specification and API (xpath and hash seems to be such ones).
One of open questions is whether to have streamlets in relpipe-in-filesystem when we have relpipe-tr-streamlet.
One tool should do one thing and we should not duplicate the effort…
But it still makes some sense because the file streamlets are specific kind of streamlets and e.g. Bash completion should suggest them if we work with files but not with other data.
And it is also nice to have all metadata collecting on the same level in a single command (i.e. --streamlet beside --file and --xattr)
than having to collect basic and extended file attributes using single command and collect other file metadata using different command.
Parallel processing
There are two kinds of parallelism: over attributes and over records.
Because streamlets are forked processes, they are quite naturally parallelized over attributes.
We can e.g. compute SHA-1 hash in one streamlet and SHA-256 hash in another streamlet and we will utilize two CPU cores (or we can ask one streamlet to compute both SHA-1 and SHA-256 hashes and then we will utilize only one CPU core).
The relpipe-in-filesystem tool simply 1) feeds all streamlet instances with the current file name, 2) streamlets work in parallel and then 3) the tool collects results from all streamlets.
But it would not be enough. Today, we usually have more CPU cores than heavy attributes (like hashes). So we need to process multiple records in parallel. The first design proposal (not implemented) was that the tool will simply distribute the file names to STDINs of particular streamlet processes in the round-robin fashion and processes will write to the common STDOUT (just with a lock for synchronization to keep the records atomic – the Relational pipes data format is specifically designed for such use). This will be really simple and somehow helpful (better than nothing). But this design has a significant flaw: the tool is not aware of how busy particular streamlet processes are and will feed them with tasks (file names) equally. So it will work satisfactorily only in case that all tasks have similar difficultness. This is unfortunately not the usual case because e.g. computing a hash of a big file takes much more time than computing a hash of a small file. Thus some streamlet processes will be overloaded while other will be idle and in the end whole group will be waiting for the overloaded ones (and only one or few CPU cores will be utilized). So this is not a good way to go.
The solution is using a queue. The tool will feed the tasks (file names in the relpipe-in-filesystem case) to the queue
and the streamlet processes will fetch them from the queue as soon as they are idle.
So we will utilize all the CPU cores all the time (obviously if we have more records than CPU cores, which is usually true).
Because our target platform are POSIX operating systems (and primary one is GNU/Linux), we choose POSIX MQ as the queue.
POSIX MQ is a nice and simple technology, it is standardized and really classic. It does not require any broker process or any third-party library so it does not bring additional dependencies – it is provided directly by the OS.
However, fallback is still possible:
a) if we set --parallel 1 (which is default behavior), it will run directly in a single process without the queue;
b) the POSIX MQ have quite simple API so it is possible to write an adapter and port the tool to another system that does not have POSIX MQ and still enjoy the parallelism (or simply reimplement this API using shared memory and a semaphore).
We could add another queue to the output side and use it for serialization of the stream (which flows to the single STDOUT/FD). But it is not necessary (thanks to the Relational pipes format design) and would add just some overhead. So on the output side, we use just a POSIX semaphore (and a lock/guard based on it). Thus the tool still has no other dependencies than the standard library and the operating system.
If we still have idle CPU cores or machines and need even more parallelism, streamlets can fork their own sub-processes, use threads or some technology like MPI or OpenMP.
However, simple parallel processing of records (--parallel N) is usually more than suitable and efficiently utilize our hardware.
XPath modes
Both relpipe-in-xmltable and the xpath streamlet uses XPath language to extract values from XML documents.
There are several modes of value extraction:
-
string: this is default option, simply the text content -
boolean: the value converted to a boolean in the XPath fashion; -
raw-xml: a portion of original XML document; this is a way to put multiple values or any structured data in a single attribute; if the XPath points to multiple nodes, it can still be returned as a valid XML document using a configurable wrapper node (so we can return e.g. all headlines from a document) -
line-number: number of the line where given node was found; this can be used for referencing particular place in the document -
xpath: XPath pointing to particular node; it would be a different XPath expression than the original one (which might point to a set of nodes); this can also be used for referencing particular place in the document
Both tools share the naming convention and are configured in a similar way – using e.g. relpipe-in-xmltable --mode raw-xml or --streamlet xpath --option mode raw-xml.
Feature overview
Data types
- boolean ~ since v0.8
- variable-length signed integer (SLEB128)
- string in UTF-8 ~ since v0.8
Inputs
- Recfile ~ since v0.11
- XML ~ since v0.9
- XMLTable ~ since v0.13
- CSV ~ since v0.9
- file system ~ since v0.9
- CLI ~ since v0.8
- fstab ~ since v0.8
- SQL script ~ since v0.14
Transformations
- sql: filtering and transformations using the SQL language ~ since v0.13
- awk: filtering and transformations using the classic AWK tool and language ~ since v0.12
- guile: filtering and transformations defined in the Scheme language using GNU Guile ~ since v0.10
- grep: regular expression filter, removes unwanted records from the relation ~ since v0.8
- cut: regular expression attribute cutter (removes or duplicates attributes and can also DROP whole relation) ~ since v0.8
- sed: regular expression replacer ~ since v0.8
- validator: just a pass-through filter that crashes on invalid data ~ since v0.8
- python: highly experimental ~ since v0.8
Streamlets
- xpath (example, unstable)
- hash (example, unstable)
- jar_info (example, unstable)
- mime_type (example, unstable)
- exiftool (example, unstable)
- pid (example, unstable)
- cloc (example, unstable)
- exiv2 (example, unstable)
- inode (example, unstable)
- lines_count (example, unstable)
- pdftotext (example, unstable)
- pdfinfo (example, unstable)
- tesseract (example, unstable)
Outputs
- ASN.1 BER ~ since v0.11
- Recfile ~ since v0.11
- CSV ~ since v0.9
- tabular ~ since v0.8
- XML ~ since v0.8
- nullbyte ~ since v0.8
- GUI in Qt ~ since v0.8
- ODS (LibreOffice) ~ since v0.8
New examples
Backward incompatible changes
The data format has changed: SLEB128 is now used for encoding numbers.
If the data format was used only on-thy-fly, no additional steps are required during upgrade.
If the data format was used for persistence (streams redirected to files), recommended upgrade procedure is:
convert files to XML using old version of relpipe-out-xml and then convert it from XML back using new version of relpipe-in-xml.
Installation
Instalation was tested on Debian GNU/Linux 10.2. The process should be similar on other distributions.
# Install dependencies as root:
su -c "apt install g++ make cmake mercurial pkg-config"
su -c "apt install libxerces-c-dev" # needed only for relpipe-in-xml module
su -c "apt install guile-2.2-dev" # needed only for relpipe-tr-guile module; guile-2.0-dev also works but requires a patch (see below)
su -c "apt install gawk" # needed only for relpipe-tr-awk module
su -c "apt install libxml++2.6-dev" # needed only for relpipe-in-xmltable module
su -c "apt install libsqlite3-dev" # needed only for relpipe-tr-sql module
# Run rest of installation as a non-root user:
export RELPIPE_VERSION="v0.15"
export RELPIPE_SRC=~/src
export RELPIPE_BUILD=~/build
export RELPIPE_INSTALL=~/install
export PKG_CONFIG_PATH="$RELPIPE_INSTALL/lib/pkgconfig/:$PKG_CONFIG_PATH"
export PATH="$RELPIPE_INSTALL/bin:$PATH"
rm -rf "$RELPIPE_BUILD"/relpipe-*
mkdir -p "$RELPIPE_SRC" "$RELPIPE_BUILD" "$RELPIPE_INSTALL"
# Helper functions:
relpipe_download() { for m in "$@"; do cd "$RELPIPE_SRC" && ([[ -d "relpipe-$m.cpp" ]] && hg pull -R "relpipe-$m.cpp" && hg update -R "relpipe-$m.cpp" "$RELPIPE_VERSION" || hg clone -u "$RELPIPE_VERSION" https://hg.globalcode.info/relpipe/relpipe-$m.cpp) || break; done; }
relpipe_install() { for m in "$@"; do cd "$RELPIPE_BUILD" && mkdir -p relpipe-$m.cpp && cd relpipe-$m.cpp && cmake -DCMAKE_INSTALL_PREFIX:PATH="$RELPIPE_INSTALL" "$RELPIPE_SRC/relpipe-$m.cpp" && make && make install || break; done; }
# Download all sources:
relpipe_download lib-common lib-reader lib-writer lib-cli lib-xmlwriter in-cli in-fstab in-xml in-xmltable in-csv in-filesystem in-recfile out-gui.qt out-nullbyte out-ods out-tabular out-xml out-csv out-asn1 out-recfile tr-cut tr-grep tr-python tr-sed tr-validator tr-guile tr-awk tr-sql
# Optional: At this point, we have all dependencies and sources downloaded, so we can disconnect this computer from the internet in order to verify that our build process is sane, deterministic and does not depend on any external resources.
# Build and install libraries:
relpipe_install lib-common lib-reader lib-writer lib-cli lib-xmlwriter
# Build and install tools:
relpipe_install in-fstab in-cli in-fstab in-xml in-xmltable in-csv in-recfile tr-cut tr-grep tr-sed tr-guile tr-awk tr-sql out-nullbyte out-ods out-tabular out-xml out-csv out-asn1 out-recfile in-filesystem
# Load Bash completion scripts:
for c in "$RELPIPE_SRC"/relpipe-*/bash-completion.sh ; do . "$c"; done
# Enable streamlet examples:
export RELPIPE_IN_FILESYSTEM_STREAMLET_PATH="$RELPIPE_SRC"/relpipe-in-filesystem.cpp/streamlet-examples/
# Clean-up:
unset -f relpipe_install
unset -f relpipe_download
unset -v RELPIPE_VERSION
unset -v RELPIPE_SRC
unset -v RELPIPE_BUILD
unset -v RELPIPE_INSTALL
# Compute hashes of your binaries in parallel:
find /bin/ -print0 | relpipe-in-filesystem --parallel 8 --file path --file size --streamlet hash | relpipe-out-csv
Download: examples/release-v0.15.sh
Relational pipes are modular thus you can download and install only parts you need (the libraries are needed always).
Tools out-gui.qt and tr-python require additional libraries and are not built by default.
Relational pipes, open standard and free software (C) 2018-2025 GlobalCode